本文的讲述都是以 Node.js 环境为例子,而 Node.js 使用的 JavaScript 引擎是 V8,因此理论上 Chrome 也能适用,其它浏览器我就不清楚了。
¶现状
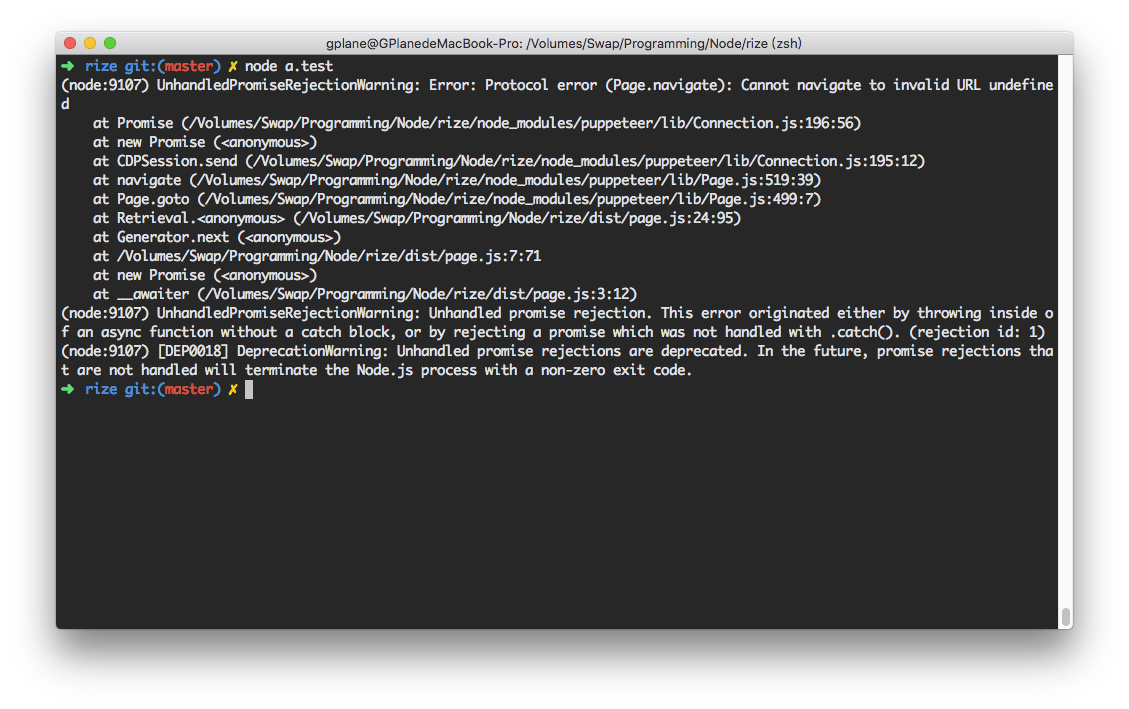
最近在写 Rize 的时候,一直为错误的栈追踪而愁。为什么呢?这要从 Rize 的架构说起。
由于 puppeteer 的绝大多数操作和 API 是异步的,而写异步代码的良好写法是用 ES2017 的 async/await 语法。
但我们都知道,async/await 实际上返回的是一个 Promise(即使你没有显式地 return 什么,它将是 Promise<void>)。很明显这样不能达到我想要的 API 链式调用的效果。我总不能对着 Promise 实例操作 prototype,然后把我自己的 API 挪上去吧?
所以我使用了一个队列来保存用户想要进行的操作。也就是说,用户在调用 Rize 的 API 之后,并不会(也不可能)立即执行这些操作,而是放在队列中,等待时机适合(例如浏览器已经启动或者上一个操作已经完成)才执行。由于送入队列的是函数,因此在 push 的参数可以放心地使用 async/await。
但是,一旦这些操作中出现错误,错误的定位变得十分麻烦。
下面这张图是直接用 Node.js 运行一个脚本的结果:
下面这张图是在 Jest 中执行一段代码的结果:
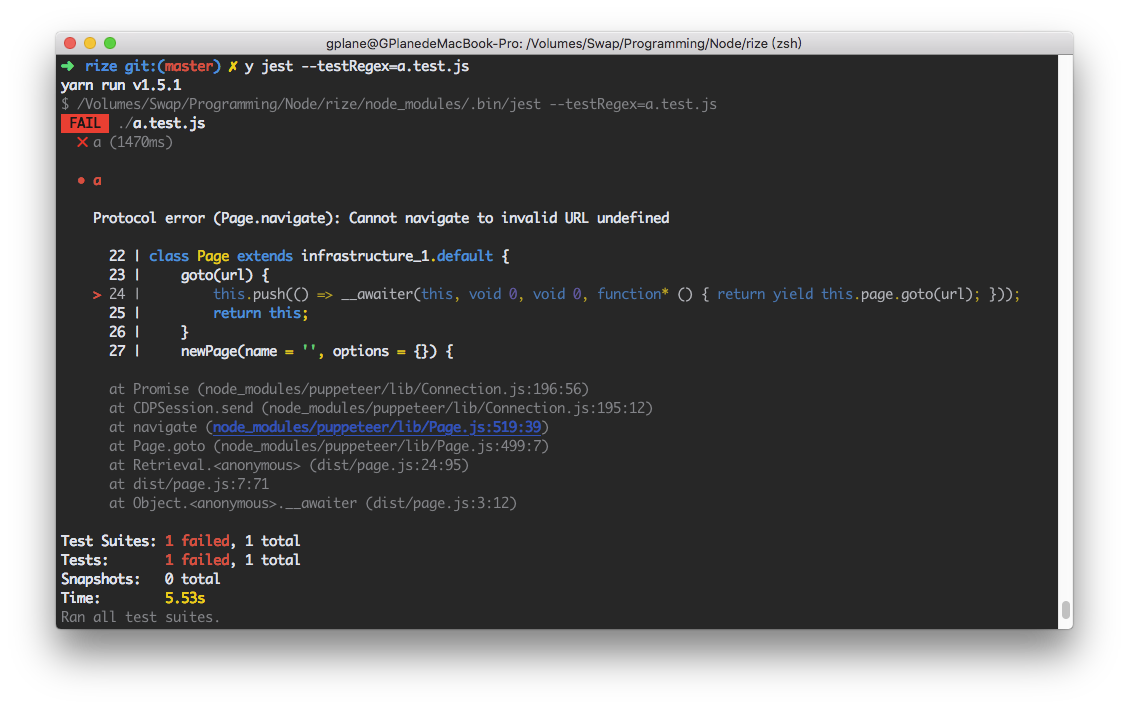
原因是,
首先,队列中的函数是 async function,这本来就给 debug 带来麻烦。
其次,这些函数并不是立即在 API 中调用的,而是由专门的队列处理代码来调用。在错误发生时,V8 只能跟踪到那段队列处理代码那里。
这就为用户带来麻烦。错误发生了,却只能看着错误消息一点一点地去试着定位有问题的地方。身为库的作者,多多少少应该为下游用户/开发者负责。
¶探索
为此我去阅读了 Node.js 的官方文档,看了 Errors 这一部分,不过似乎没什么收获。
后来又找到了 TJ Holowaychuk 大神写的库 callsite,看看能不能有用。从文档上看,这个库并不适合我的需求。
但我阅读了 callsite 的源码,源码很短,十行不到。我在源码发现了一些信息。
callsite 是利用 V8 的 Stack Trace API 来获取函数调用处的一些信息,如文件名,行号等等。callsite 是如何获取这些数据的呢?
非常简单,就一句:
var err = new Error()对,仅仅是 new 一个 Error 实例,而且并不是要抛出这个错误。
对比我们平时的代码,通常当我们 throw 一个错误之后,我们能得到一些错误栈信息。但实际上,不需要 throw,仅仅是新建一个 Error 实例,也能让 V8 记录下当前的调用栈信息。
¶解决
既然发现这个事实,那我们可以在需要记录调用栈的地方 new 一个 Error 实例。(千万不要把它抛出,不然你后面的代码就没法执行了)
此时当前的栈信息已经被记录下来,那么我们怎样去使用这些信息呢?
如果用户的代码执行正常,那就没什么关系了。关键是在发生错误的时候。这里要提一提的是,我的那段队列处理代码是带有 try…catch 块的,大概长这样:
try {
await fn()
} catch (error) {
throw error
} finally {
// do some stuff ...
}你可能好奇什么要把捕捉的异常还要抛出,因为我想要的是后面的 finally 块啊,但同时我又希望异常能继续被抛出。
在这里,我们就要对 catch 块做点功夫。当然这个 try…catch 块是能够获取到之前新建的 Error 实例的,在这里我省略了那部分代码。
为了方便叙述,我把之前 new 的那个 Error 实例命名为 trace,即假设 const trace = new Error()。
显然把 trace 的所有栈信息都拿过来是不适合的,因为它有一些我们并不需要的栈信息(这部分信息是位于 API 调用处以上的)。
每一个 Error 实例都有个 stack 属性,它是一个多行字符串,我们先把它的每行分开,保存在数组中:
const stack = trace.stack!.split('\n')要注意 stack 的第一行不是栈信息,而是错误消息,这个不能去掉。所以:
stack.splice(1, 2)我这里有两行的信息是没用的,所以删去两行,实际上要根据你的需要修改第二个参数。
现在可以把 trace 的栈信息替换掉实际 error 的栈信息:
error.stack = stack.join('\n')¶结果
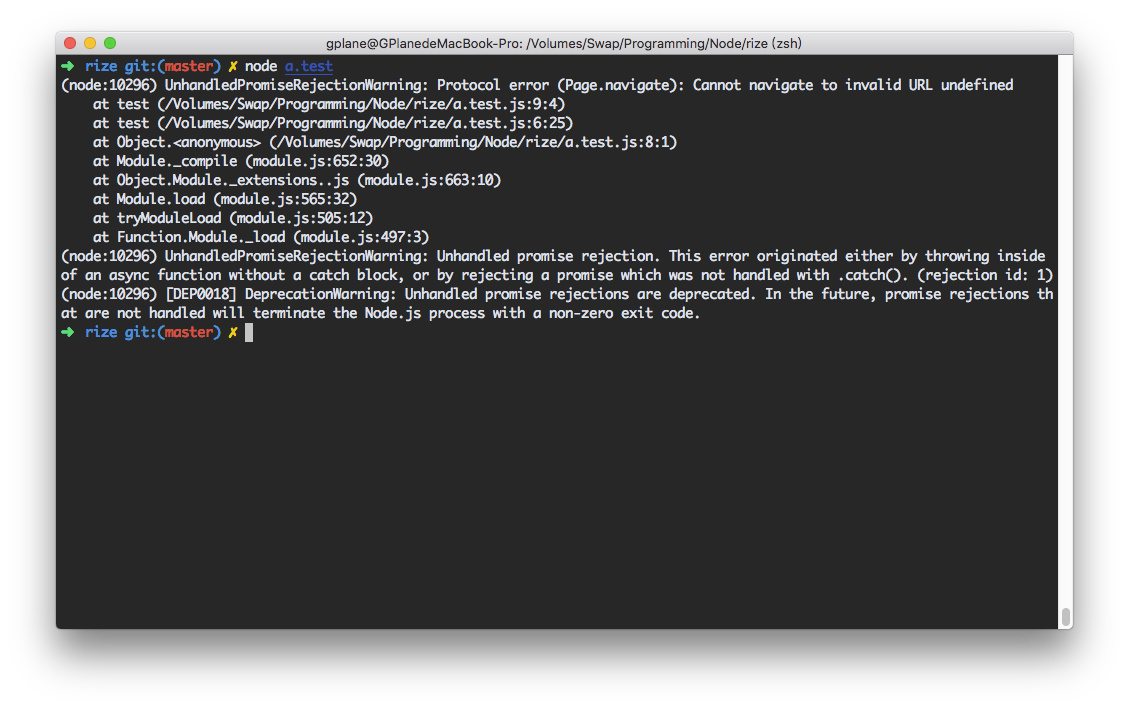
现在就可以得到友好的错误栈信息了:
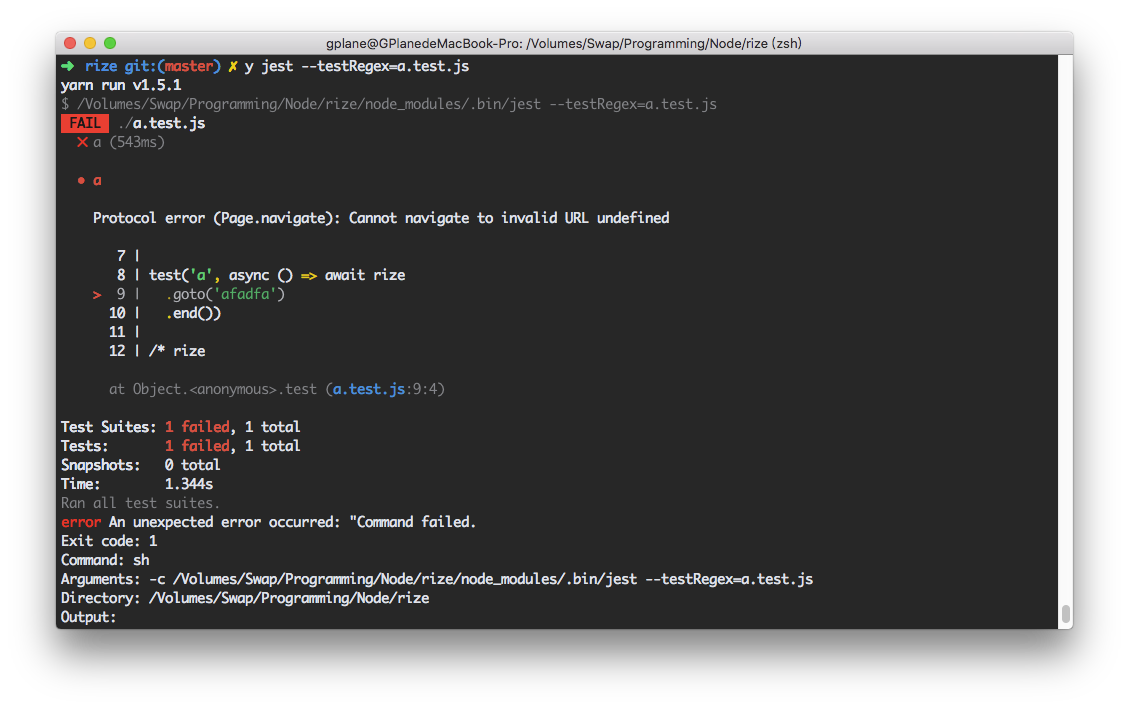
配合 Jest 就能更好地定位问题所在之处:
以上。